简答题
考虑下表所示二元分类问题的数据集。
 (1)计算按照属性A和B划分时的信息增益。决策树归纳算法将会选择哪个属性? (2)计算按照属性A和B划分时Gini系数。决策树归纳算法将会选择哪个属性?
(1)计算按照属性A和B划分时的信息增益。决策树归纳算法将会选择哪个属性? (2)计算按照属性A和B划分时Gini系数。决策树归纳算法将会选择哪个属性?正确答案
按照属性A和B划分时,数据集可分为如下两种情况:

按照属性A划分样本集分别得到的两个子集(A取值T和A取值F)的信息熵分别为:

按照属性B划分样本集分别得到的两个子集(B取值T和B取值F)的信息熵分别为:

因此,决策树归纳算法将会选择属性A。
(2)
划分前的Gini值为G=1-0.42-0.62=0.48
按照属性A划分时Gini指标:
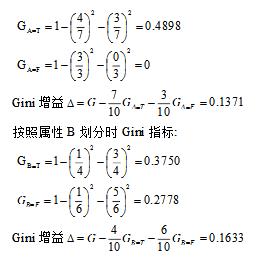
因此,决策树归纳算法将会选择属性B。

按照属性A划分样本集分别得到的两个子集(A取值T和A取值F)的信息熵分别为:

按照属性B划分样本集分别得到的两个子集(B取值T和B取值F)的信息熵分别为:

因此,决策树归纳算法将会选择属性A。
(2)
划分前的Gini值为G=1-0.42-0.62=0.48
按照属性A划分时Gini指标:
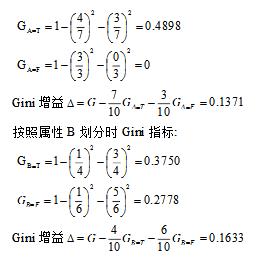
因此,决策树归纳算法将会选择属性B。
答案解析
略